

Real-Time Data Integration
For Enterprise-Grade ETL
Enterprise data teams should not have to fight brittle pipelines, slow batch jobs, and complex streaming systems just to keep data fresh. Tabsdata delivers real-time consistent data through a simple pub/sub model for tables.


Real-Time Data You Can
Actually Trust
Deliver live insights, detect fraud faster, personalize in-session, and keep ML features fresh without the brittleness of batch pipelines or complexity of streaming systems.
Infrastructure you can trust
Trusted by data teams in e-commerce,
logistics, finance, and more
Designed for speed
Cut real-time data latency
from hours to seconds
Why Real-Time Data is Still Hard
Most teams still rely on slow batch pipelines or complex streaming stacks. Pipelines are brittle and break with even small changes. Streaming systems demand specialists and force tradeoffs between accuracy and speed. As things shift, data drifts, dashboards lag, and ML features go stale. The result is the same: real-time data never arrives when the business needs it.
Pipelines are brittle and slow
Streaming frameworks are costly and complex
Real-time, consistent data is difficult to maintain
Real-Time Data Integration
Without the Streaming Headaches


What is Tabsdata? Your Enterprise Real-Time ETL Platform
Tabsdata is an enterprise-grade platform that moves data the moment it becomes available, guaranteeing that all departments receive fresh and pertinent data as soon as possible. Instead of stitching together jobs, DAGs, and streaming frameworks, Tabsdata uses a table-centric Pub/Sub model to keep every system – dashboards, AI models, fraud engines, and operational tools – continuously in sync.
It works across traditional databases, logs, SaaS apps, APIs, and IoT sources, delivering reliable real-time data without orchestration overhead, pipeline fragility or complex streaming infrastructure. Tabsdata fits into your existing stack, enhancing it rather than replacing things.
Real-Time ETL That Runs Where Your Data Lives
Tabsdata deploys in your cloud, hybrid environment, or on-premises, keeping data inside your network and aligned with enterprise security processes, and governance requirements.
From Events to Tables in Seconds, Not Hours
New data, including transactions, events, and updates, is captured as configured and turned into structured tables. These are propagated in real time, so that every downstream system sees the same consistent views.
Key Benefits for
Data-Driven Enterprises
Modern businesses require speed, reliability, and consistency across systems in this data-driven world. Tabsdata enables your team to replace brittle pipelines and slow refresh cycles with real-time foundation that is easier to manage, simpler to scale and optimized for operational and AI workloads. Here are the benefits enterprises gain when data moves as soon as it becomes available:
Eliminate Data Latency Across
Dashboards, AI, and Operations
At Tabsdata, we ensure data flows seamlessly to the core systems that require it. This means dashboards stay live, anomaly detection runs in real time, and personalization engines respond within the same session. By removing batch windows and lag, every team works from the most accurate information possible.
Reduce Streaming Infrastructure
Cost and Complexity
Tabsdata removes the need to build event-processing applications that trade accuracy for speed and require heavy streaming-processing engines. You can implement complex transformation and preparation logic directly in Tabsata, reducing both latency and the cost of pre-processing data inside your platform. With every update fully traceable, it reduces the time to diagnose and fix any issues that creep in.
Gain Predictable, Reproducible Dataflows
All tables in Tabsdata are versioned, immutable, and fully reproducible. Teams can time-travel, debug logic, and reprocess history with confidence, ensuring every consumer sees the exact same consistent state. This removes guesswork and eliminates any downstream discrepancies that normally appear when data changes out of sync.
Build AI and ML on Fresh, Trusted Data
Tabsdata keeps feature tables, training sets, and inference data aligned by delivering updates in real time through consistent, versioned tables. ML teams get reliable inputs without waiting for batch jobs or maintaining streaming pipelines, reducing feature drift and simplifying how models are fed. This makes it easier to ship and maintain ML use cases without overhauling existing infrastructure.

How Tabsdata Reinvents Real-Time ETL
Traditional ETL and streaming systems rely on complex, imperative pipelines – endless jobs, DAGs, and orchestration logic, all to simply move data from one system to another. Tabsdata replaces all of that with Pub/Sub for Tables, the new way to build real-time dataflows where tables are the core unit of change.
This shift reduces operational strain on the streaming infrastructure, creating a solid foundation that automatically ensures every system is synced up.
From Imperative Pipelines to Declarative
Pub/Sub for Tables
Traditionally, in legacy architectures, teams write long instructional chains, dictating precisely how and when data should move. With Tabsdata, publishers simply create or update tables, letting consumers subscribe to the tables they depend on. Updates propagate immediately without the need for manual coordination. Instead of stitching together brittle workflows, teams define desired data relationships and let the platform handle consistency, timing, and propagation. This reduces overhead, eliminating pipeline failures long-term.
From Imperative Pipelines to
Declarative Pub/Sub for Tables
Every version of each table in Tabsdata is immutable and traceable. Teams can inspect lineage, understand exactly where data came from, replay history, or reprocess changes, and all without disrupting existing systems. This degree of reproducibility is almost impossible via traditional pipelines, where reprocessing is risky and labor intensive.
End-to-End Metadata, Ownership, and Dataflow Intelligence
Tabsdata preserves metadata, semantics, and ownership across the dataflow. Quality signals, utilization metrics, and freshness indicators are built-in, providing data leaders with full visibility over how datasets perform. This transforms datasets into manageable products rather than unclear pipelines. Teams can gain centralized intelligence to help them optimize performance and uphold cross-organization standards.
Features of the Tabsdata Real-Time ETL Platform
Tabsdata unites real-time transformation, ingestion, governance, and delivery into a single platform. Instead of having to manage multiple tools and pipelines, teams benefit from an end-to-end integration layer designed for speed, security, and reliability.

Real-Time ETL Use Cases Tabsdata Powers
Tabsdata brings real-time dataflow to life across a range of analytical, operational, and AI-driven environments. By delivering data in real-time, teams can eliminate lag, reduce risk, and unlock insights that batch systems simply can’t provide. Here are some of the high-impact use cases Tabsdata provides.

Live Operational Dashboards and KPI Monitoring
Tabsdata keeps dashboards continuously updated by delivering new transactions, events, and operational data as it becomes available. Executives and operations teams no longer wait for regular refresh cycles. Instead, metrics reflect the current status of the business, faster decision, earlier detection of issues, and greater responsiveness.

Fraud, Anomaly, and Cybersecurity Detection in Real Time
By delivering up-to-date data directly into fraud engines and anomaly detection systems, Tabsdata ensures teams react to suspicious activity as soon as it appears. Instead of relying on delayed batch scans, risk teams get live context that helps block fraudulent transactions, detect threats sooner, and strengthen security posture.

Real-Time Customer Experience and Personalization
Customer events arrive in real time and update personalization engines instantly. This allows marketing, product, and CX teams to deliver recommendations, dynamic pricing, bespoke offers, and more relevant user experiences that improve engagement and retention.

Logistics, IoT, and Asset Visibility
Sensor data, device updates, and inventory movements flow through Tabsdata as they become available. This provides teams with an accurate, real-time view of assets and operations. Logistics, manufacturing, and supply chain teams gain live visibility that reduces delays, improves forecasting, and coordinates resources more effectively.

AI and ML Feature Freshness
Tabsdata keeps model features, inference inputs, and training sets aligned. ML teams rely on low-latency, consistent data, improving model accuracy, and unlocking new predictive use cases. With the added ability to replay history and correct logic quickly; experimentation becomes safer and far more efficient.

Product Tour of Our Real-Time ETL Platform
Tabsdata makes real-time dataflows simple to design, monitor, and operate. With a clear, table-centric model and intuitive interface, teams can build reliable data relationships, and understand how information and data move across the business.
Design Real-Time Dataflows
with Pub/Sub for Tables
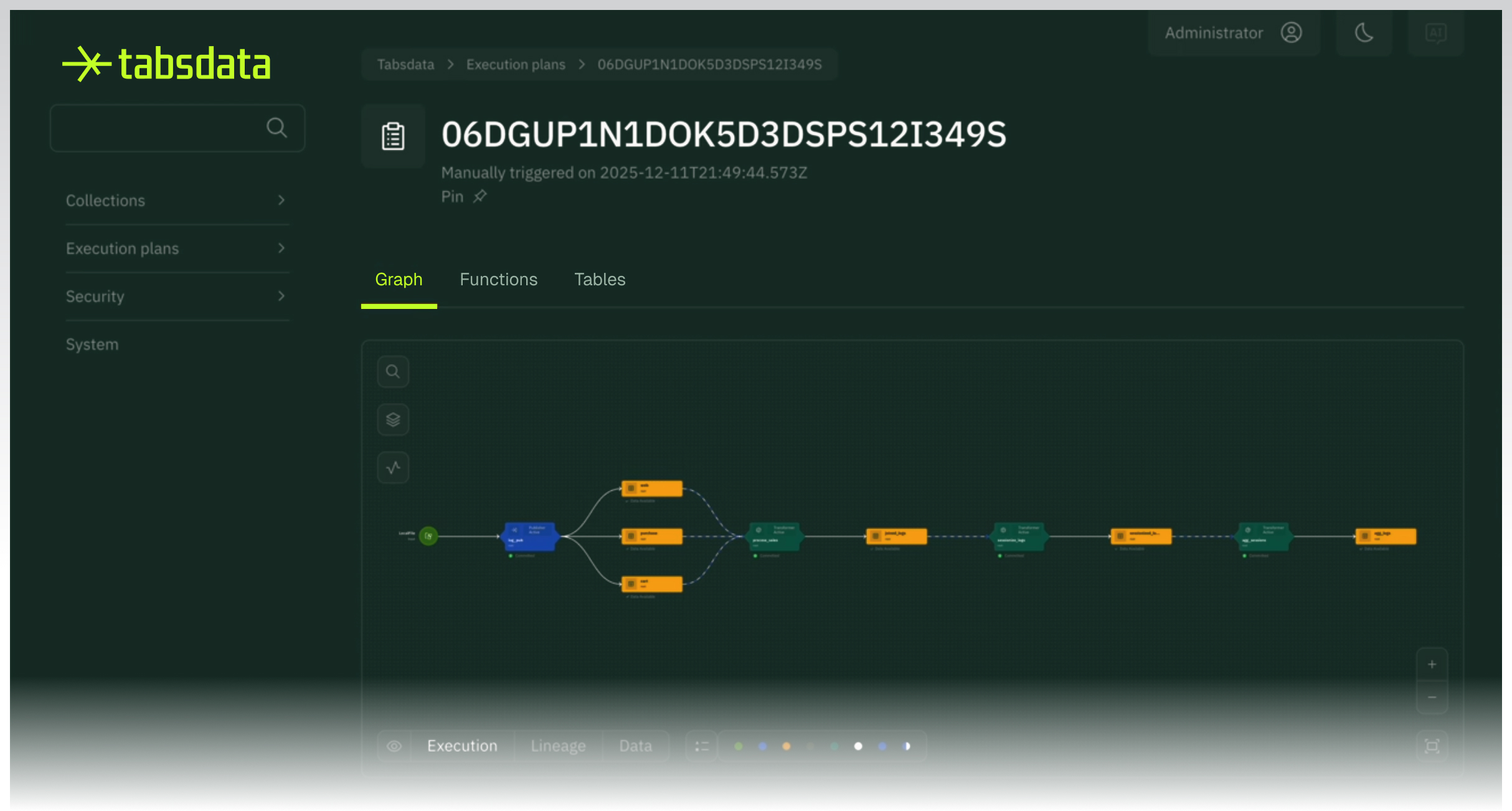
In Tabsdata, tables are the core unit of data propagation. When a publisher updates a table, dependent tables automatically receive the new version based on the relationships defined in your dataflow. Transformations run without pipelines or orchestration, and the platform manages dependencies and consistency for you. The visual execution plan shows the dependencies and order of operations, so engineers can see exactly how each table is updated. Once complete, the execution plan becomes the table’s lineage, capturing the versions and states involved so the entire dataflow is fully reproducible.
Monitor Freshness, Quality, and Utilization in One Place
Tabsdata provides built-in dashboards showing freshness, latency, errors, and quality checks across each flow. Teams will be able to spot issues quickly, trace them to source, and understand which datasets drive the most impact. With a unified view of flow health and usage, data leaders maintain trust, reduce resolution time, and keep real-time pipelines optimized.
Real-Time Data Integration Without the Streaming Headaches
Tabsdata is built for enterprise teams requiring dependable, real-time data powering analytics, operations, and AI. The table-centric approach reduces complexity for technical teams, while giving business leaders trust and clarity to make decisions better.

For Data and Analytics Leaders (CIO, CDO, VP Data)
Tabsdata helps leaders reduce costs, improve data trust, and remove operational overhead from struggling pipelines. With built-in governance and observability, leaders gain visibility and control across their entire data estate.
For Data Architects and Engineers
Tabsdata removes the complexity of managing brittle pipelines, orchestrators, and mixed workloads. Engineers define relationships instead of writing endless jobs, making dataflows more predictable.
For ML, Fraud, and Product Teams
Operational, ML, and product teams rely on Tabsdata for continuously updated features and real-time insights. Data arrives fresh and consistent, enabling more accurate models, better fraud detection, and customer experiences that respond immediately to user behavior.
Tabsdata vs. Other Enterprise Data Integration Platforms

Implementation, Security, and Time to Value
Tabsdata is designed to fit smoothly into pre-existing enterprise environments, delivering real-time value without disruption or compromise.
Deployment Models and Cloud Environments
Tabsdata supports cloud, hybrid, and on-prem environments, integrating cleanly with AWS, GCP, Azure, and private infrastructure with ease.
Onboarding, PoCs, and
Migration Support
Teams receive guided onboarding, structured PoCs, and staged rollout support to replace fragile dataflows with minimal operational risk or downtime.
Security, Compliance, and Data Governance
Tabsdata keeps data inside your environment, with enterprise features such as role based access control, audit logging, and governance controls to ensure adherence to security and compliance essentials.

Ready to Rethink Real-Time ETL?
Enterprise data teams should not have to fight brittle pipelines, slow batch jobs, and complex streaming systems just to keep data fresh. Tabsdata delivers real-time consistent data through a simple pub/sub model for tables.
Frequently asked questions
Everything you need to know about the product and billing.
What is real-time ETL?
Real-time ETL is the process of moving and transforming data as soon as it becomes available, instead of waiting for scheduled batch jobs. Unlike traditional ETL, which runs hourly or daily, real-time ETL updates downstream tables continuously so applications, dashboards, and ML models always see fresh data. It reduces latency, avoids long pipeline chains, and makes data available to business with minimal delay as updates flow through.
How is real-time ETL different from batch ETL?
Batch ETL runs on a fixed schedule, often hourly or daily, pulling large volumes of data through pipelines that operate in discrete chunks. Real-time ETL processes data as soon as it becomes available, reducing the delay between when data is produced and when it can be used. Batch ETL is simpler but slower and prone to data inconsistencies and staleness, while real-time ETL keeps downstream systems fresher without waiting for scheduled jobs or large batch processing windows.
Why do enterprises need real-time ETL?
Enterprises need real-time ETL because many decisions now depend on up-to-date operational data. Batch pipelines introduce inconsistencies and delays, causing dashboards to lag, ML features to drift, and business workflows to react too slowly. Real-time ETL reduces this latency by keeping downstream systems continuously current, which supports faster detection of issues, better customer experiences, and more reliable data for analytics, machine learning, and AI.
What are the main challenges with traditional ETL?
Traditional ETL depends on scheduled batch jobs, which makes data slow to update and hard to keep consistent as systems change. Pipelines become brittle over time, breaking when schemas shift or new sources are added, and they require constant maintenance to stay reliable. Because each job runs in isolation, it’s difficult to trace lineage, manage dependencies, or guarantee that the downstream consumers see a consistent, up-to-date view of the data.
What are the main challenges with streaming pipelines?
Streaming pipelines are powerful but difficult to build and operate at scale. They require specialized skills, constant tuning, and careful management of state, ordering and fault recovery. Small changes in schemas or data volumes can ripple into outages, and debugging issues across distributed components is slow and unpredictable. As they grow, these systems become costly to maintain, and many teams struggle to keep them accurate, reliable, and aligned with downstream consumers.
How does Tabsdata’s Pub/Sub for Tables model work?
Tabsdata uses tables as the unit of data propagation. When an upstream table is updated, the platform automatically identifies which downstream tables depend on it and generates new versions for them. Transformations run on complete, consistent inputs, and Tabdata manages dependency tracking, ordering, and propagation without pipelines or orchestration. This keeps dataflows simple, reliable and fully reproducible.
How does Tabsdata’s Pub/Sub for Tables model work?
Tabsdata uses tables as the unit of data propagation. When an upstream table is updated, the platform automatically identifies which downstream tables depend on it and generates new versions for them. Transformations run on complete, consistent inputs, and Tabdata manages dependency tracking, ordering, and propagation without pipelines or orchestration. This keeps dataflows simple, reliable and fully reproducible.
How is Tabsdata different from other real-time ETL tools?
Most real-time ETL tools rely on pipelines, jobs, and streaming engines to move data, which makes them complex to build and expensive to operate. Tabsdata takes a different approach: it uses tables as the unit of propagation, automatically updating downstream tables whenever upstream tables change. There are no DAGs, no orchestration layers, and no streaming infrastructure to maintain. Because all tables are versioned and consistent, Tabsdata delivers real-time data with built-in lineage, reproducibility, and far lower operational overhead than traditional real-time systems.
What sources and destinations does Tabsdata support?
Tabsdata connects seamlessly to transactional databases, SaaS apps, APIs, log and IoT feeds, and delivers them to systems that require them.
Tabsdata connects seamlessly to filesystems, object stores, databases, SaaS applications and specialized systems like message brokers and IoT systems. For a full list of systems that Tabsdata connects with, refer to the Publisher and Subscribers section of documentation available at docs.tabsdata.com.How does Tabsdata handle data quality, lineage, and observability?
Tabsdata evaluates every update through a system-generated execution plan. As each plan runs, Tabsdata records the exact table versions and transformation code used, creating a complete execution artifact. When the dataflow finishes successfully, that artifact becomes the table’s lineage, giving teams a precise and reproducible history of how each version was produced. Tabsdata also supports table-level quality checks that run automatically with every new version, with results stored alongside the table’s metadata for easy inspection and monitoring.
How long does it take to implement Tabsdata?
Most teams can get started with Tabsdata in a matter of days, since the platform doesn’t require pipelines, orchestration setups, or bespoke streaming infrastructure. A small proof of concept usually involves connecting one or two sources, defining a few transformations, and publishing the outputs into your existing systems. Full implementation depends on the number of dataflows you want to migrate. Many teams roll out Tabsdata incrementally over a few weeks or months, expanding as they see value and gain confidence in the model.
How is Tabsdata priced?
Tabsdata is priced per core of execution, grouped in 8 core increments. For more information, see the pricing page.
Can Tabsdata replace our existing ETL/streaming stack or work alongside it?
Tabsdata can work alongside your current ETL and streaming systems or gradually replace parts that no longer meet your performance or maintenance needs. Most teams begin with workloads that need fresher data or are difficult to keep stable in pipelines or streaming engines. As they get comfortable with the model, many choose to simplify their stack by moving more dataflows into Tabsdata. Tabsdata works best for teams that value a declarative approach to dataflows and want the operational simplicity that comes from automatic dependency management and consistent, reproducible updates.
Still have questions?
Can’t find the answer you’re looking for? Please chat to our friendly team.